Data Augmentation
Overview
Data augmentation techniques help improve model robustness and generalization by artificially expanding your training dataset. These methods simulate realistic variations in spectral data that might occur during acquisition or processing.
Augmentation Methods
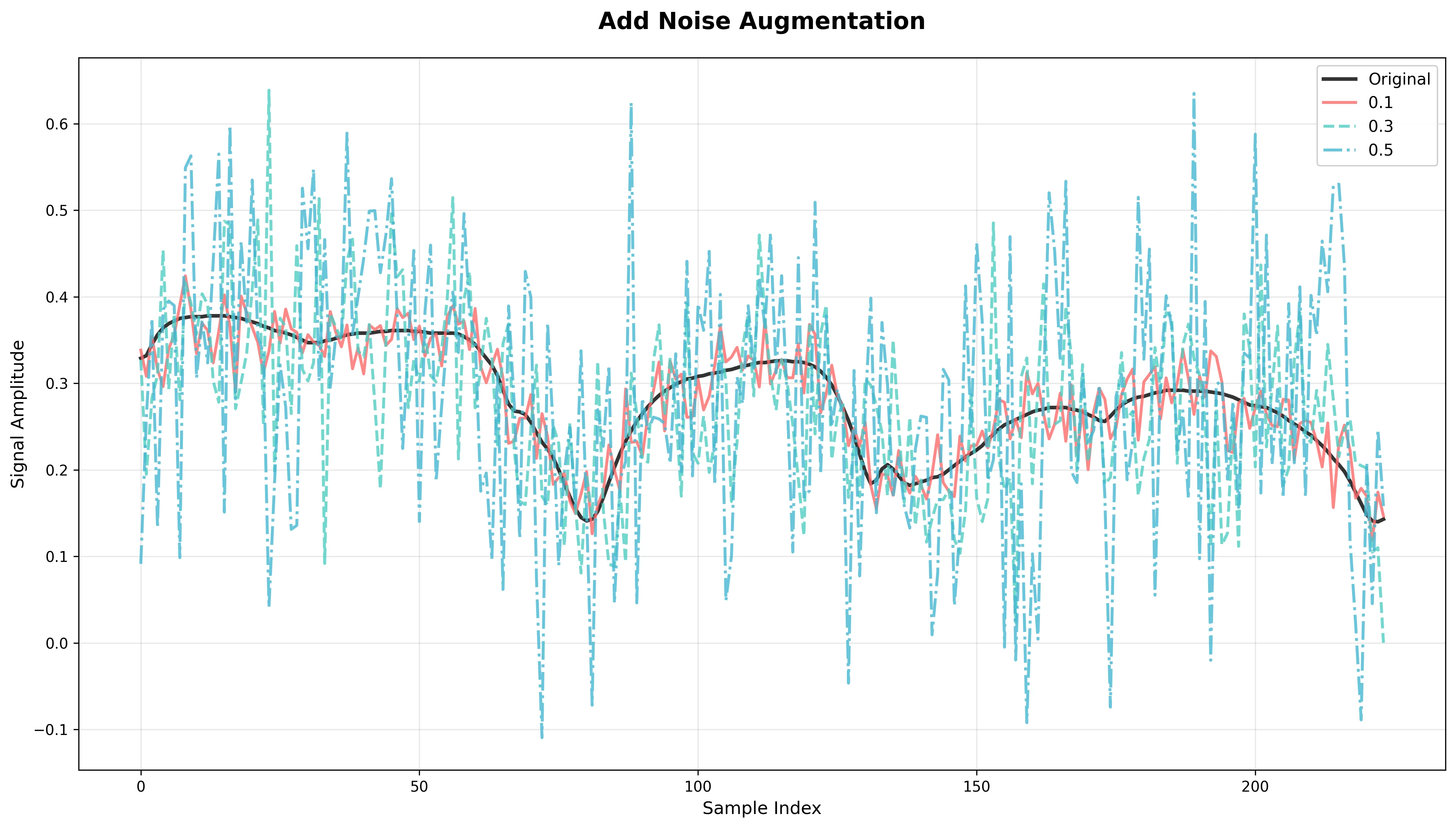
Add Noise
What it does: Adds Gaussian noise scaled to the signal's mean × noise_factor.
Effect: Simulates sensor/electronic noise, improving model robustness to noisy measurements.
Risk: Excessive noise can mask important spectral peaks and reduce model accuracy.
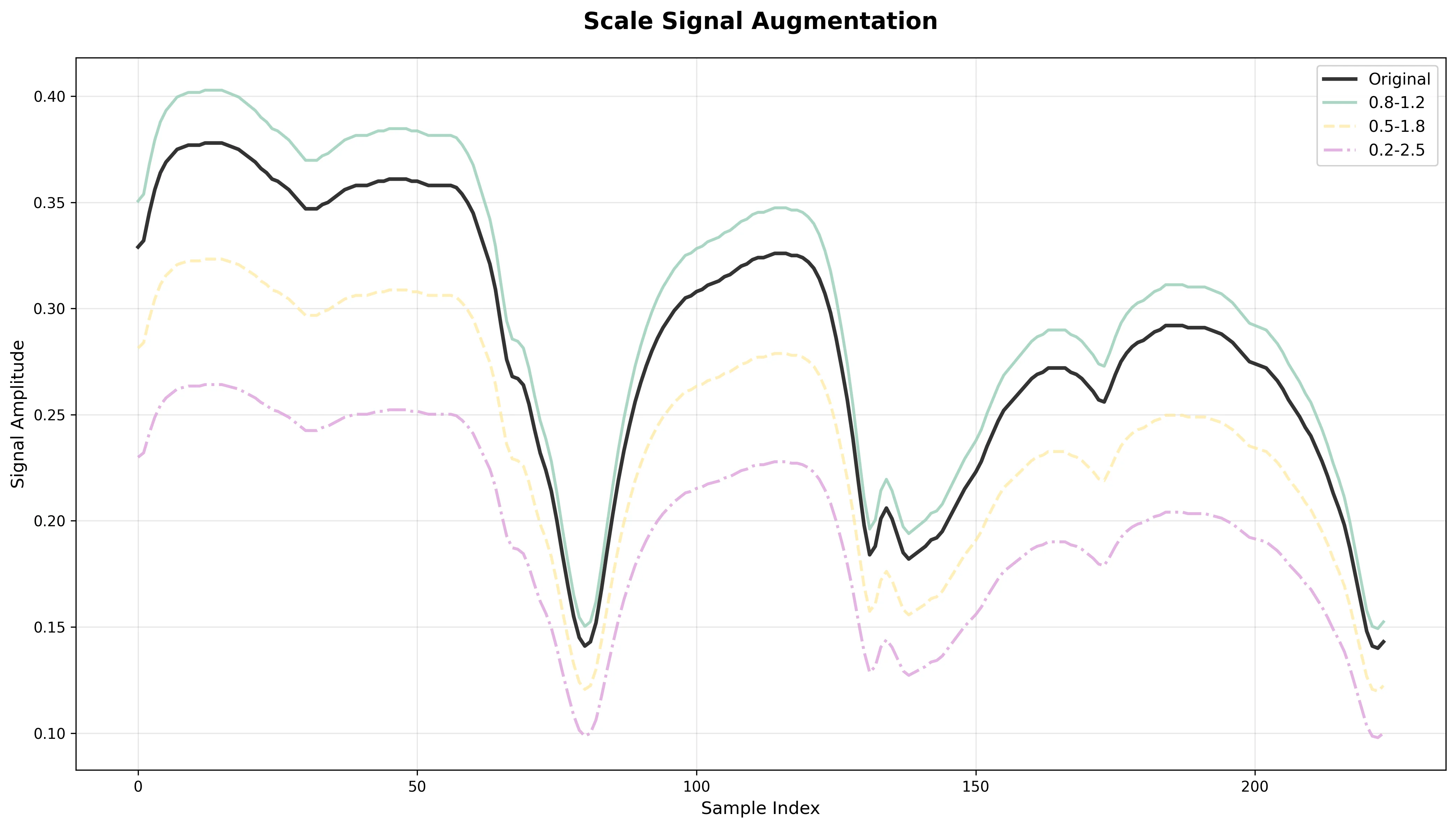
Scale Signal
What it does: Randomly multiplies the signal by a factor between scale_min and scale_max.
Effect: Simulates variations in signal intensity or gain across different acquisitions.
Risk: If the scaling range is too wide, absolute peak magnitudes (often critical for classification) may be distorted.
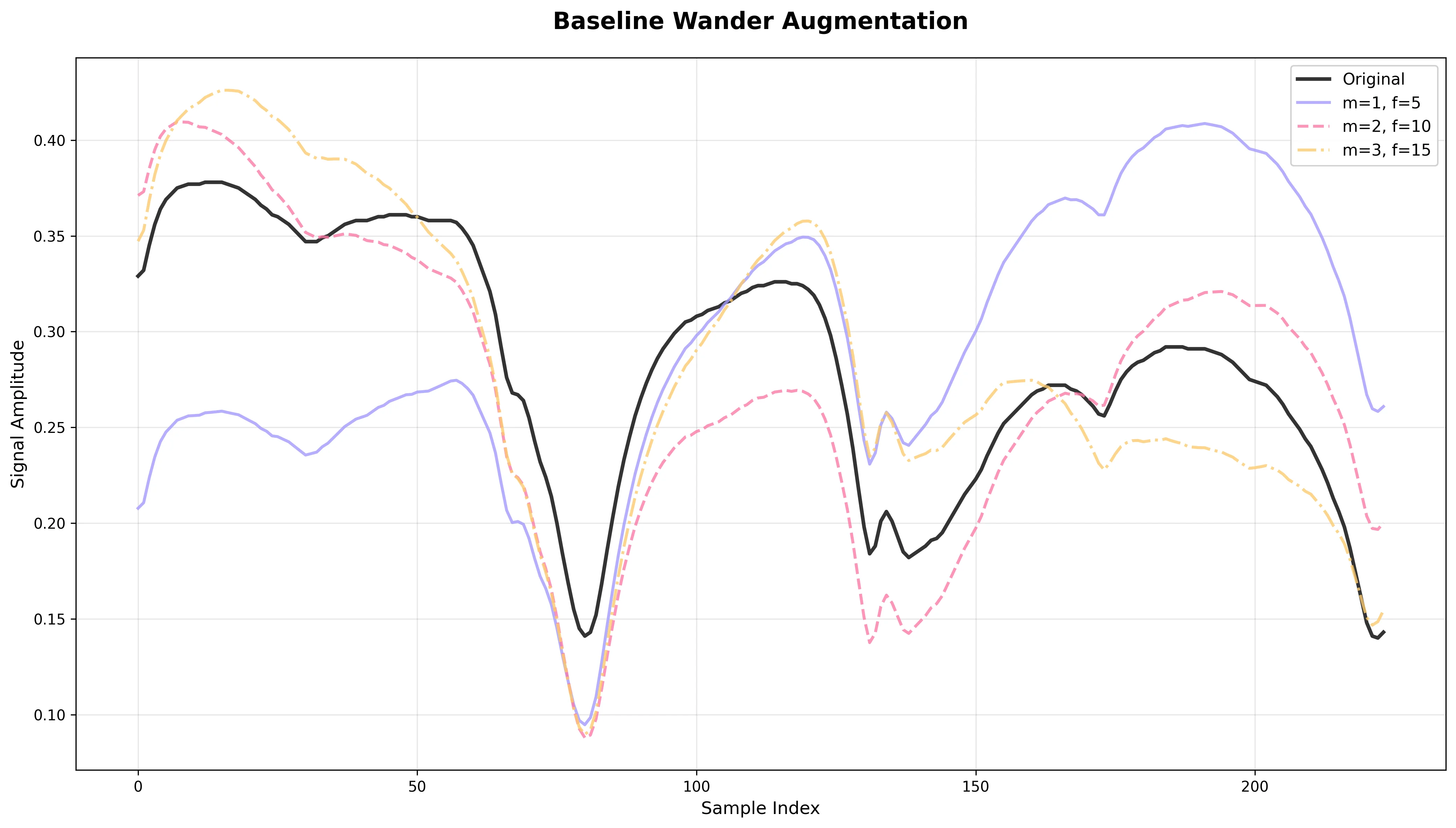
Baseline Wander
What it does: Adds a sinusoidal drift with random frequency/phase, amplitude scaled by magnitude parameter.
Effect: Simulates baseline drift common in spectroscopy and similar data acquisition systems.
Risk: Excessive drift may obscure low-frequency features that are important for classification.
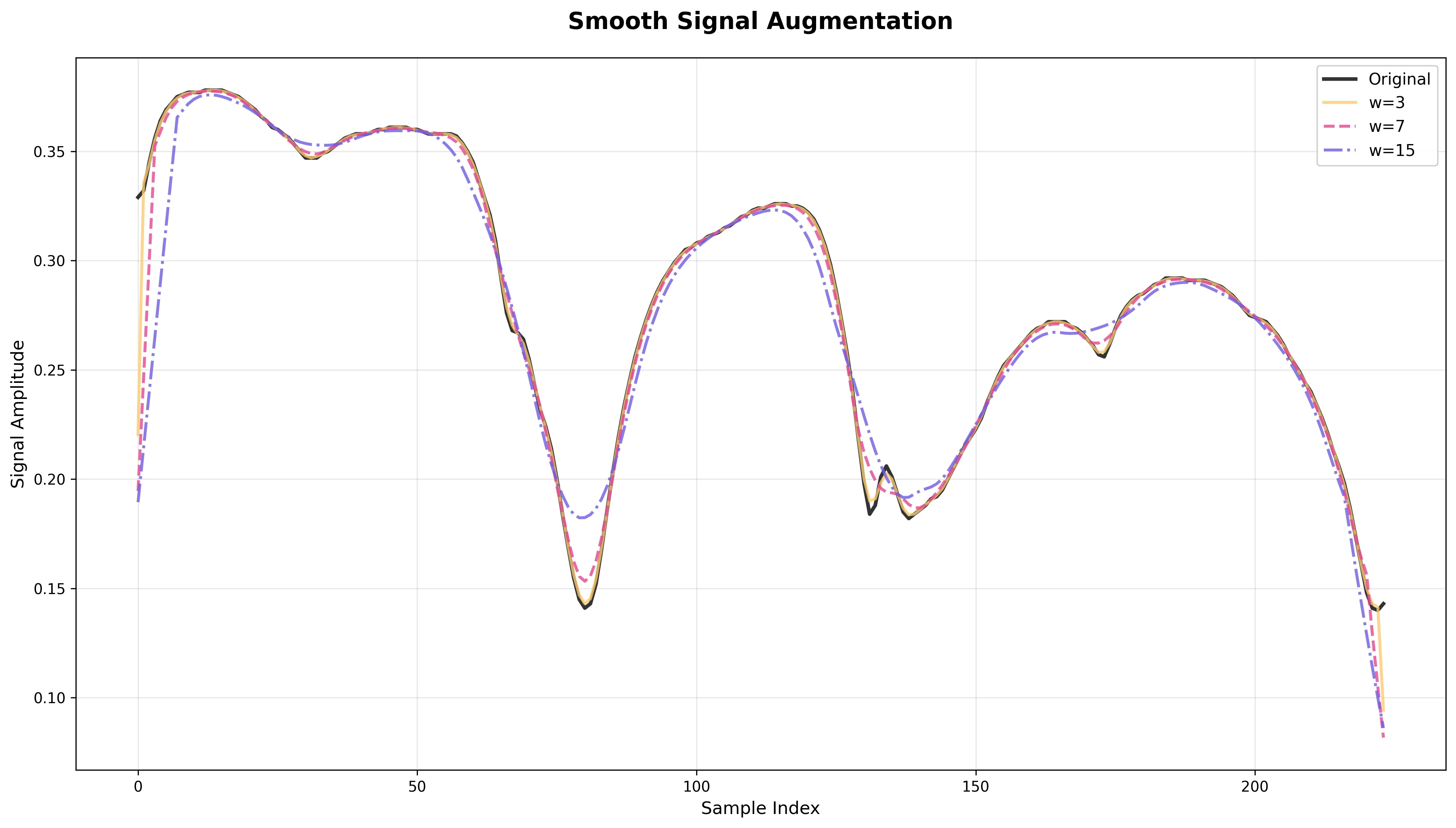
Smooth Signal
What it does: Applies moving-average smoothing with the specified window size.
Effect: Reduces noise and simulates poor spectral resolution or detector limitations.
Risk: Can blur sharp peaks and edges that are class-discriminative features.
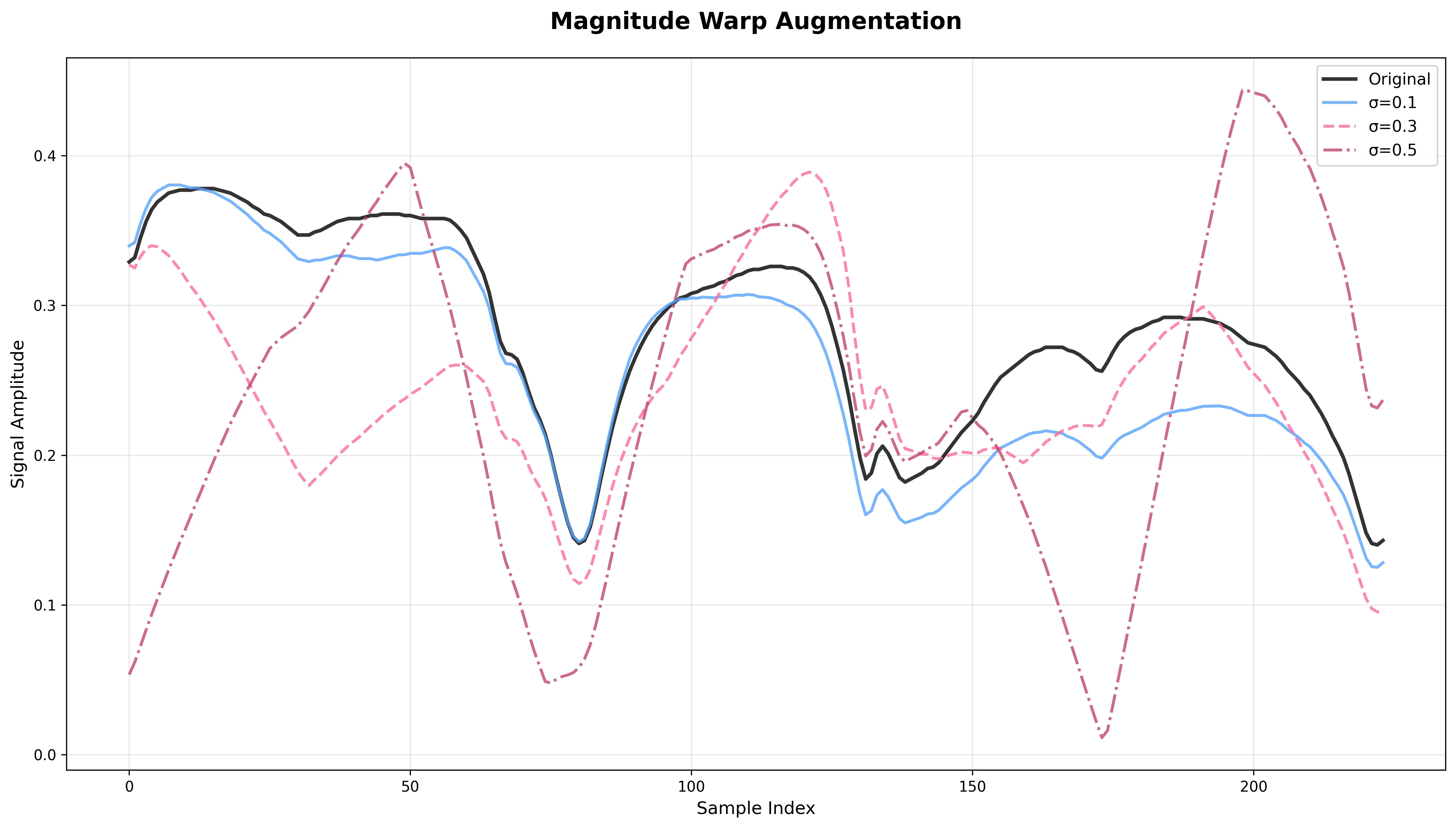
Magnitude Warp
What it does: Warps magnitude over the signal length using smooth interpolation of random scaling factors.
Effect: Simulates local scaling changes like peak broadening or uneven detector response.
Risk: May distort peak ratios, which are important discriminative features for many materials.
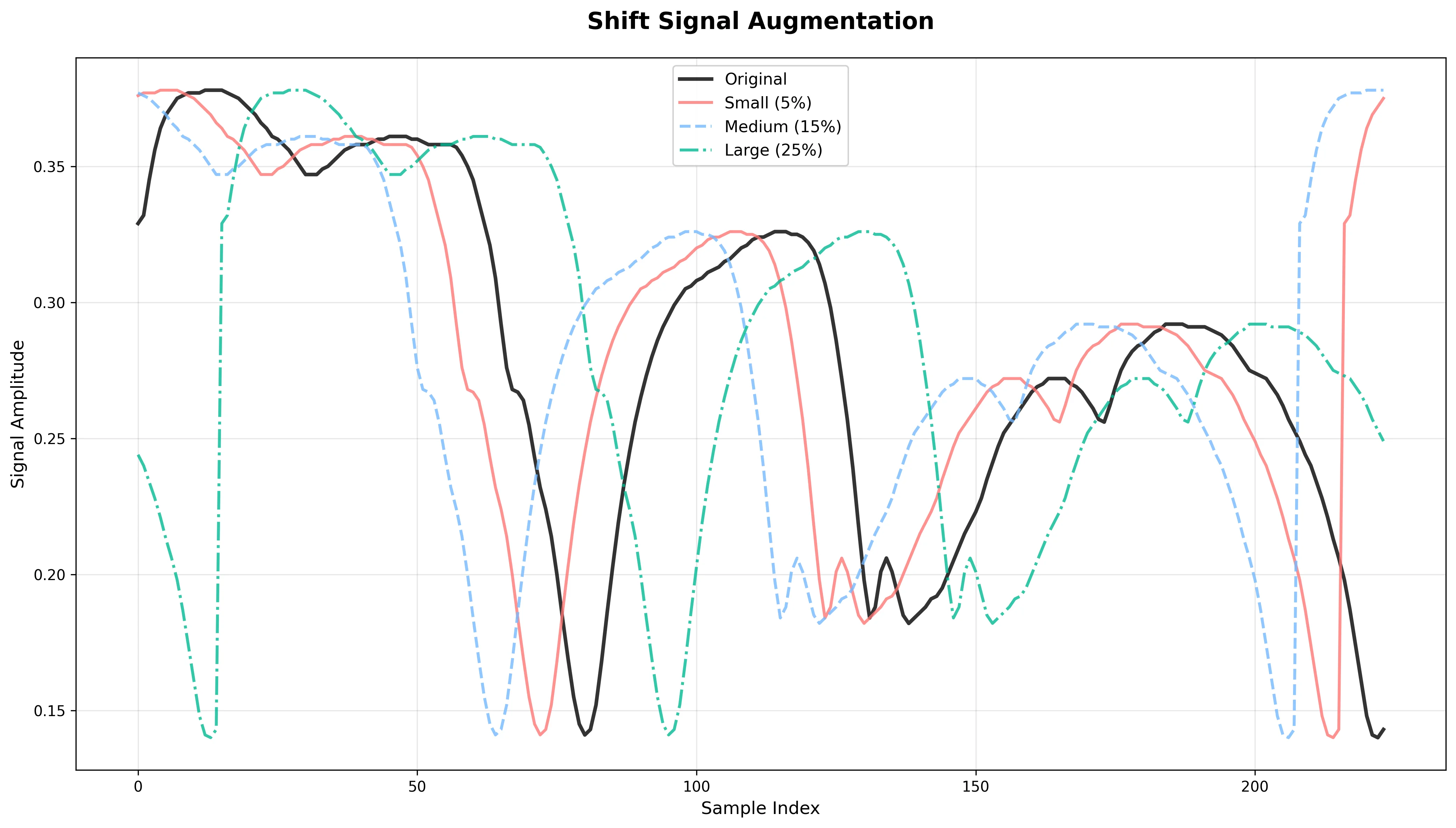
Shift Signal
What it does: Randomly rolls the signal left or right by up to shift_max × signal length.
Effect: Simulates misalignment in acquisition or temporal shifts between measurements.
Risk: For features tied to absolute spectral position, this may destroy critical information.
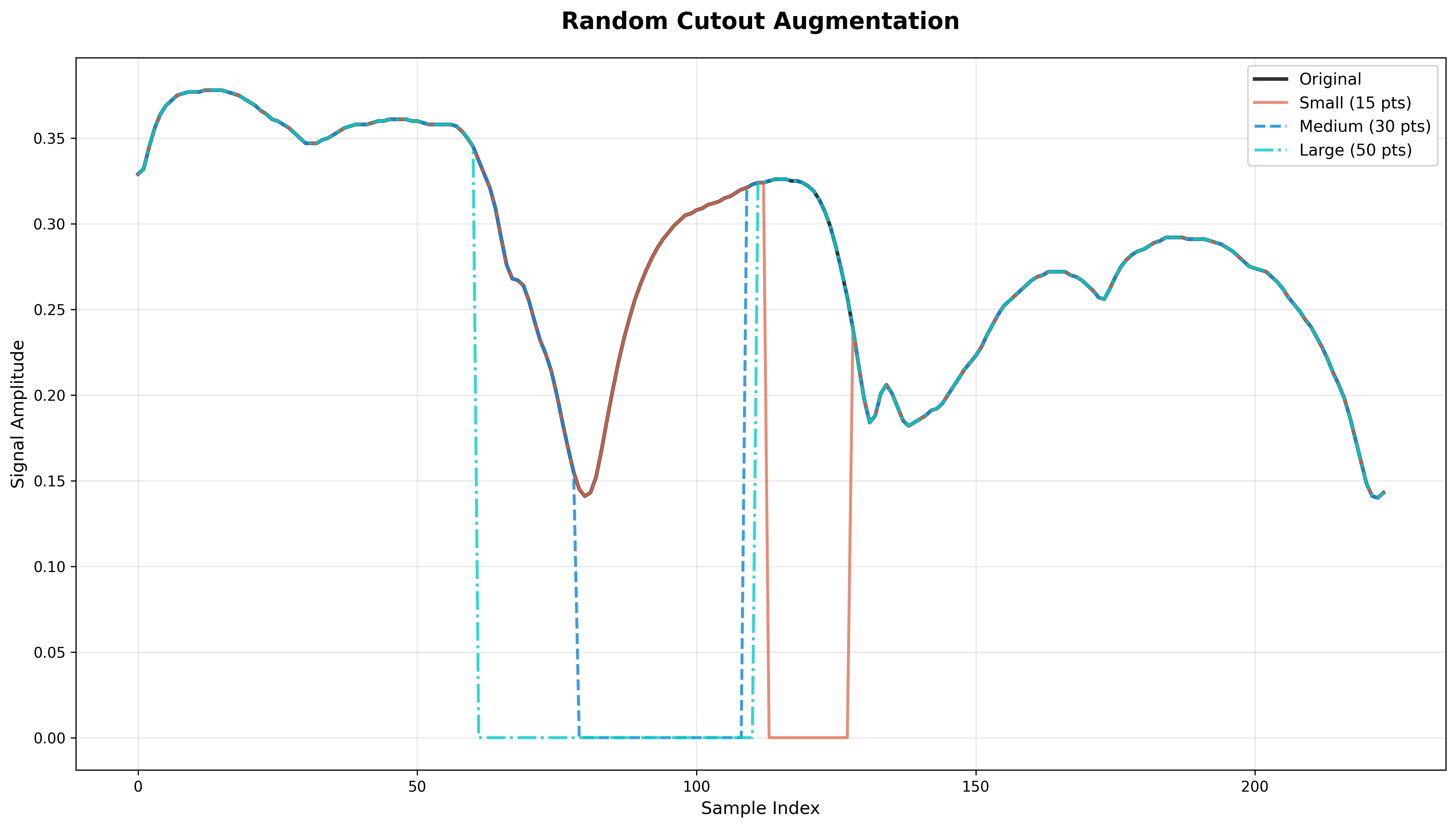
Random Cutout
What it does: Zeros out a contiguous segment of the spectrum with length mask_size.
Effect: Forces model robustness to missing bands or detector dropout scenarios.
Risk: If the cutout overlaps with critical spectral regions, classification performance may degrade.
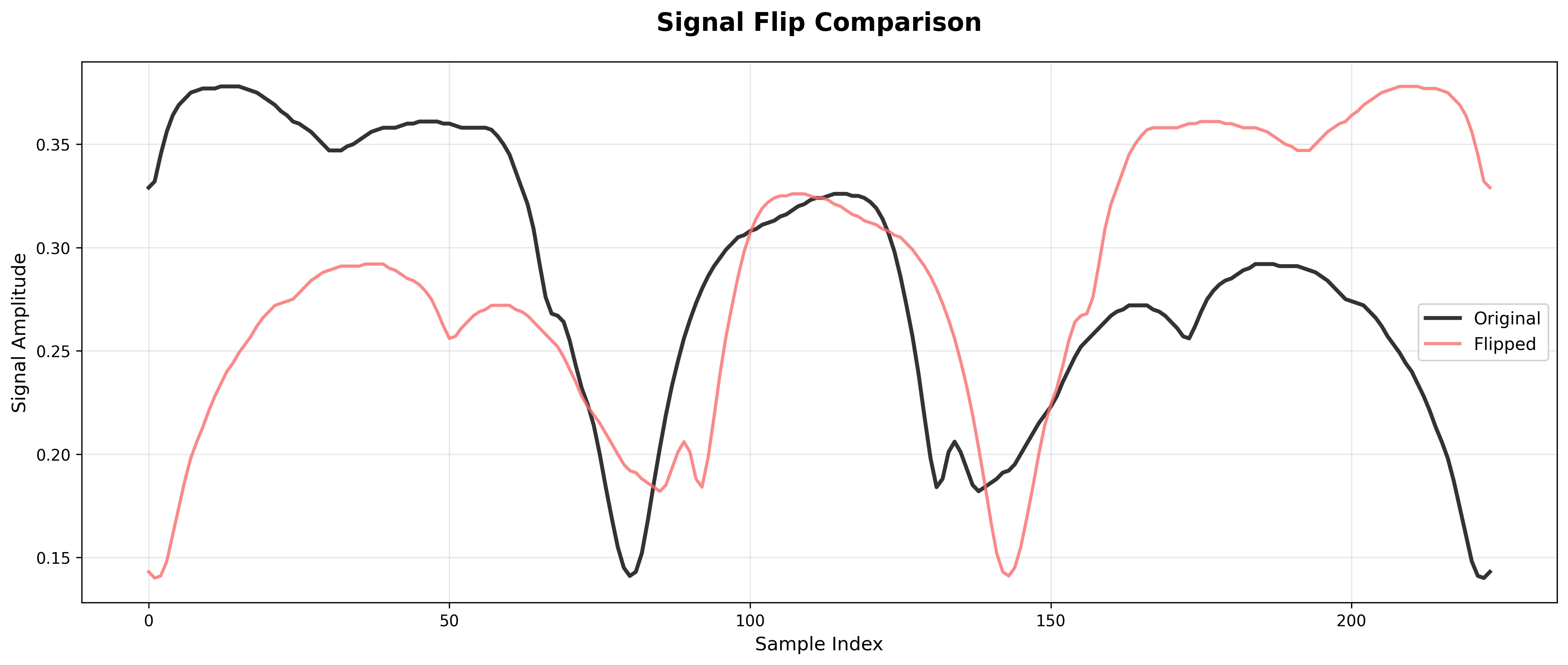
Flip Signal
What it does: Reverses the signal along the spectral axis.
Effect: Usually only meaningful if spectra or signals have symmetric properties.
Risk: Often unrealistic for spectroscopy applications; use with caution.
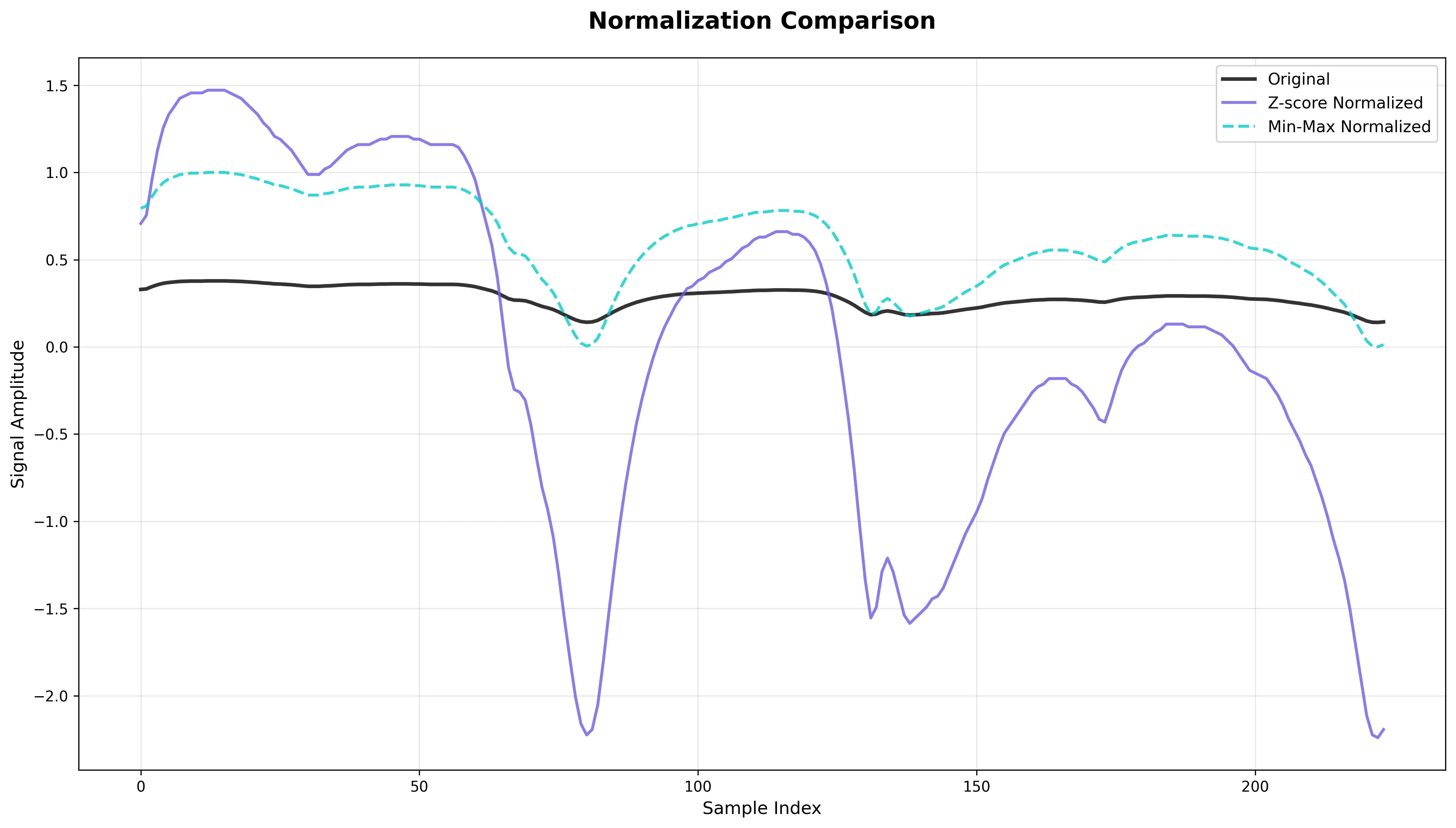
Z-score Normalization
What it does: Standardizes signal to mean 0 and standard deviation 1.
Effect: Removes scale and offset variations, stabilizes optimization during training.
Risk: Should be applied consistently across all data, not randomly during augmentation.
Min-Max Normalization
What it does: Rescales signal values to the range [0, 1].
Effect: Normalizes intensity across samples, removes absolute scale dependencies.
Risk: Can be sensitive to outliers that define the min/max range.
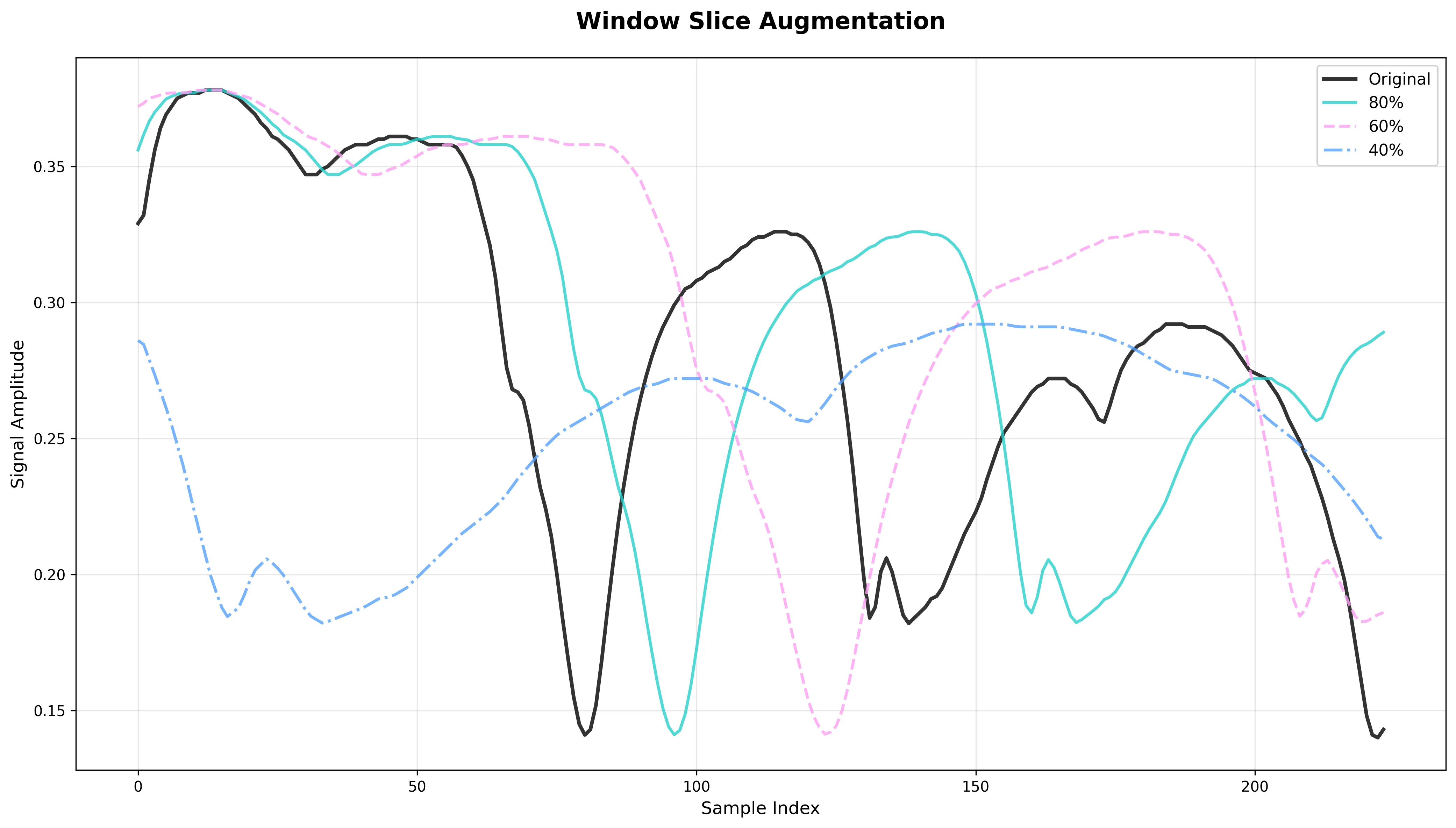
Window Slice
What it does: Randomly selects a contiguous subsequence of the signal (a "window") with length proportional to reduce_ratio. The subsequence is then rescaled/interpolated back to the original length.
Effect: Forces robustness to partial spectral information. Simulates cases where only part of the spectrum is captured (e.g., due to limited detector range).
Risk: If discriminative features lie outside the retained window, the model may lose critical classification cues. Aggressive slicing is dangerous when classes differ only by subtle spectral features.
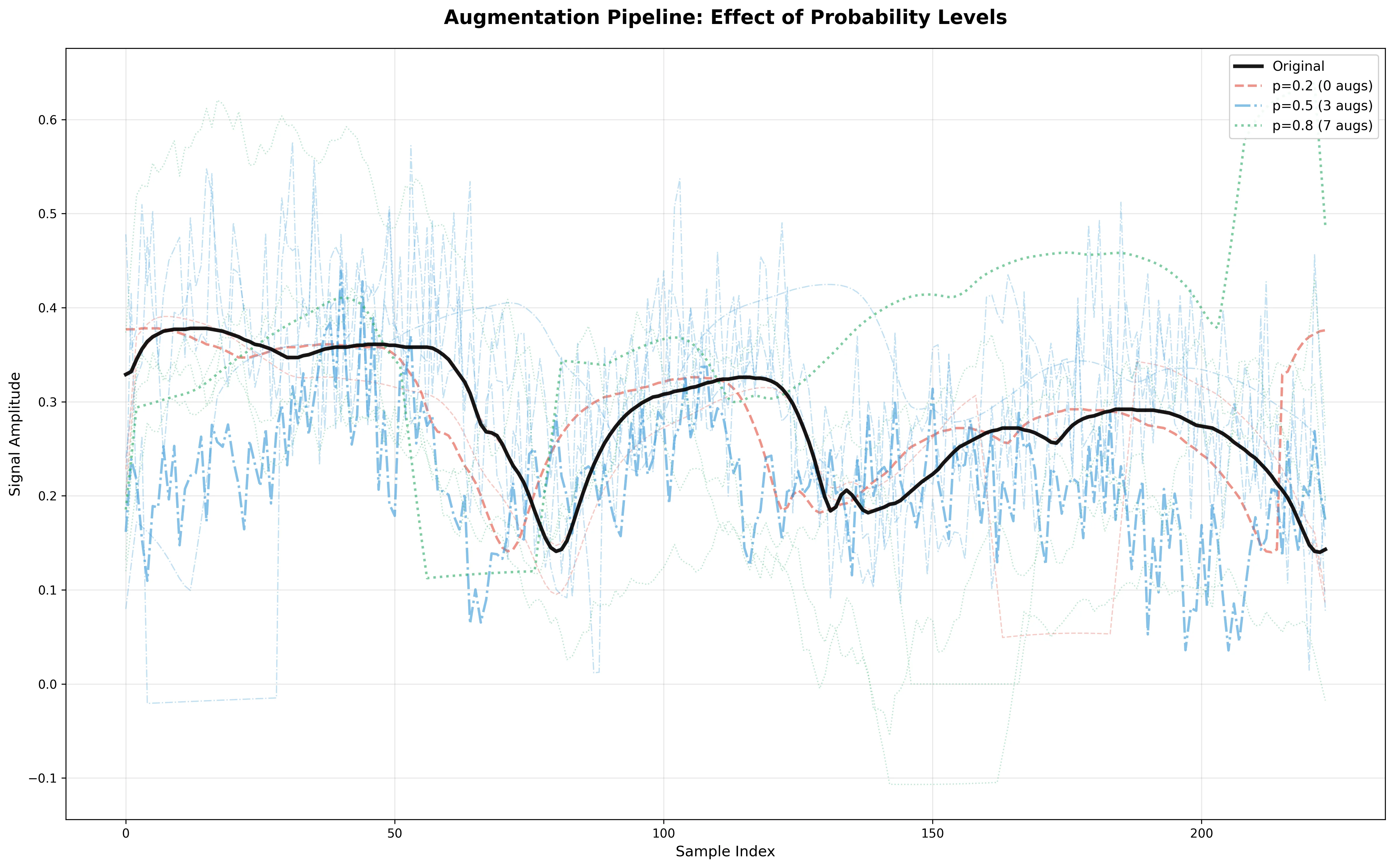
Effect of Probability Level
The probability parameter controls how frequently each augmentation is applied during training. Higher probability means more aggressive augmentation, which can improve robustness but may also introduce too much variation.
Best Practices
When to Use Augmentation
- Small datasets: Augmentation is most beneficial when you have limited training data
- Overfitting: If validation metrics plateau while training improves, augmentation can help
- Real-world variability: Use augmentation to match the noise and variation in your deployment environment
Recommended Approach
- Start conservative: Begin with low probability (10-20%) and mild parameter values
- Monitor validation: Watch validation metrics to ensure augmentation is helping, not hurting
- Match reality: Choose augmentations that reflect real acquisition conditions
- Avoid unrealistic transforms: Don't use augmentations that create impossible spectra
- Combine strategically: Use 2-3 complementary augmentations rather than all methods
Common Configurations
Moderate Augmentation Strategy
Best for: Standard training with adequate data (>5000 samples/class), moderate class similarity, general-purpose tasks
Augmentation Parameters
| Augmentation | Probability | Parameters |
|---|---|---|
| add_noise | 0.75 | noise_factor=0.3 |
| baseline_wander | 0.65 | mag=1.5, freq=10 |
| scale_signal | 0.70 | scale_min=0.5, scale_max=1.8 |
| magnitude_warp | 0.25 | sigma=0.2, knot=4 |
| smooth_signal | 0.25 | window_size=5 |
| shift_signal | 0.25 | shift_max=0.05 |
| random_cutout | 0.25 | mask_size=15 |
| window_slice | 0.25 | reduce_ratio=0.9 |
Training Recommendations
- Epochs: 80–120
- Learning Rate: 1e-3 to 5e-4 (reduce on plateau)
- Batch Size: 32–64
- Optimizer: Adam or AdamW
- Early Stopping: Patience = 15–20 epochs
- LR Schedule: ReduceLROnPlateau (factor=0.5, patience=8)
- Validation Split: 0.15–0.20
- Regularization: Dropout 0.2–0.3, L2: 1e-4
Extensive Augmentation Strategy
Best for: Small datasets (<500 samples/class), high class similarity, highly variable deployment conditions, transfer learning
Augmentation Parameters
| Augmentation | Probability | Parameters |
|---|---|---|
| add_noise | 0.90 | noise_factor=0.5 |
| scale_signal | 0.85 | scale_min=0.2, scale_max=3 |
| baseline_wander | 0.80 | mag=3, freq=15 |
| magnitude_warp | 0.70 | sigma=0.4, knot=6 |
| smooth_signal | 0.55 | window_size=7 |
| shift_signal | 0.60 | shift_max=0.1 |
| random_cutout | 0.40 | mask_size=30 |
| window_slice | 0.35 | reduce_ratio=0.75 |
| flip_signal | 0.15 | — |
| min_max_normalize | 0.4 | — |
| zscore_normalize | 0.4 | — |
Training Recommendations
- Epochs: 120–200 (slower convergence expected)
- Learning Rate: 5e-4 to 1e-4 (start lower)
- Batch Size: 64–128
- Optimizer: AdamW (weight_decay=1e-4)
- Early Stopping: Patience = 25–35 epochs
- Validation Split: 0.20–0.25
- Regularization: Dropout 0.3–0.4, L2: 5e-5
See Also
- Model Training — Learn how to configure augmentation during training
- Advanced Settings — Configure other hyperparameters
- Training Metrics — Monitor augmentation effectiveness