Adjusting and Improving Models
Overview
In the domain of statistical learning models, the first iteration of models created is rarely the best. Rather, the models can be significantly improved with adjustments after each iteration of testing. The adjustments made to the model will depend on your requirements for accuracy / precision / recall.
Versioning
Clarity supports iteration through the "Version" button available in both the Dataset and Model tabs.
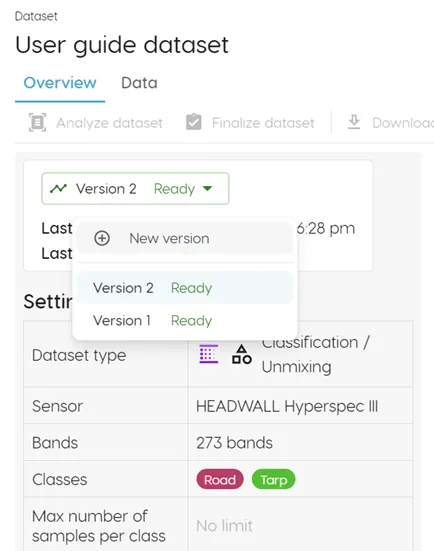
Click on the "Version" button, then "New version" to create a new iteration of either your dataset or associated model. You may want to do this if you decide to add additional selections or classes to your dataset, or train a model with different parameters. You can see each version as a toggleable layer in the Spectral Explorer page, making it easy to compare and contrast different versions of your dataset and model.
Common Improvement Strategies
Data Quality Improvements
- Add more training samples for underrepresented classes
- Improve label quality by refining existing labels
- Balance class distribution to avoid bias
- Remove noisy or mislabeled data
Model Parameter Tuning
- Adjust learning rates for better convergence
- Modify batch sizes for optimal training
- Experiment with different architectures (CNN, ResNet, LSTM, Transformer)
- Tune regularization parameters to prevent overfitting
Feature Engineering
- Select optimal wavelength ranges for your specific use case
- Apply spectral preprocessing (SNV, normalization)
- Use band selection to focus on most informative bands
- Implement spectral binning for dimensionality reduction
Iterative Improvement Process
- Train initial model with baseline parameters
- Evaluate performance using multiple metrics
- Identify weaknesses in the current model
- Make targeted improvements to data or parameters
- Retrain and compare with previous versions
- Repeat until desired performance is achieved
Performance Monitoring
Track improvements across versions by monitoring:
- Accuracy metrics (precision, recall, F1-score)
- Training curves (loss, accuracy over time)
- Confusion matrices for classification tasks
- Visual results in Spectral Explorer
- Inference performance on new data
Best Practices
- Document changes made between versions
- Test on validation data before finalizing
- Avoid overfitting by monitoring validation performance
- Consider computational costs when selecting architectures
- Validate improvements on completely new test data